Med3DVLM 模型架构及训练流程详解

Med3DVLM 是一种专为医学影像诊断设计的多模态大模型,结合了先进的图像和文本处理技术,实现了对医学影像与相关文本信息的深度理解和关联。本文将详细介绍 Med3DVLM 的模型架构及其训练流程。
训练阶段一:图文对比学习
这一阶段主要训练 Vision-Encoder 。
Vision-Encoder 图像编码器: DCFormer
DecompConv3D 分解 3D 卷积
如图,传统的 3D 卷积块的参数量为 ,可以在三个方向上进行分解,分别为 、 和 ,只保留三维中的“骨架”,参数减少为 。( 为奇数)
实际使用时,可以在图像的对应维度周围填充 个像素,以保持输入输出尺寸一致。
注意:图中的中心位置实际上有 3 个参数,分别对应三个方向的卷积核。
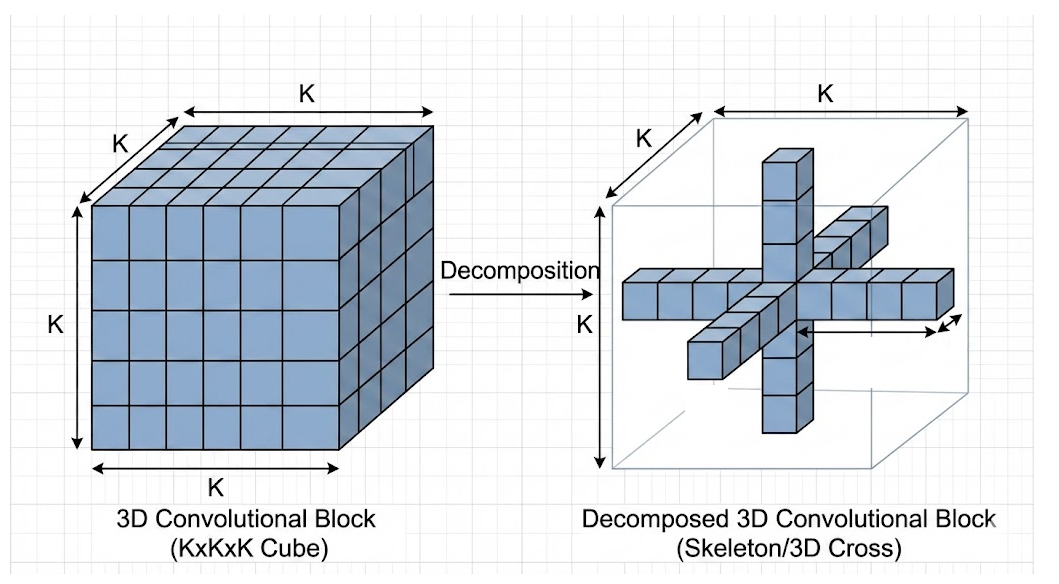
(图片为 AI 生成,有部分奇怪的地方,请见谅)
DecomposedStem 分解卷积 Stem 模块
网络中的 Stem 模块一般指模型的初始层,Stem 有“茎”的意思,表示模型的起点
假设输入数据为 (B, C_in, H, W, D) 。
B:批次大小 (Batch Size)C_in:输入通道数 (Input Channels)H, W, D:输入数据的高度、宽度和深度
| 步骤 | 参数 | 维度 | 备注 |
|---|---|---|---|
| 初始 | / | (B, C_in, H, W, D) |
输入数据 |
| DecompConv3D | kernel_size=7, stride=4 |
(B, C_out, H/4, W/4, D/4) |
下采样到 1/4 大小,通道数变为 C_out |
| DecompConv3D | kernel_size=3, stride=1 |
(B, C_out, H/4, W/4, D/4) |
保持尺寸不变,加深网络 |
| DecompConv3D | kernel_size=3, stride=1 |
(B, C_out, H/4, W/4, D/4) |
保持尺寸不变,加深网络 |
| DecompConv3D | kernel_size=3, stride=1 |
(B, C_out, H/4, W/4, D/4) |
保持尺寸不变,加深网络 |
总结:(B, C_in, H, W, D) -> (B, C_out, H/4, W/4, D/4) 。
|
|
ConvBlock 卷积块
每次分解卷积后,通道特征进入单隐藏层的 MLP,之后经过学习的缩放参数,最后通过残差连接与输入相加,形成卷积块的输出。
一般是 多 个 ConvBlock 叠起来用,在使用之前要先进行下采样和通道数调整。
1. 下采样 & 通道数调整
输入特征:(B, C_in, H, W, D) 。
| 步骤 | 参数 | 维度 | 备注 |
|---|---|---|---|
| 初始 | / | (B, C_in, H, W, D) |
输入数据 |
MaxPool3d(非分解卷积) |
kernel_size=3, stride=2 |
(B, C_in, H/2, W/2, D/2) |
下采样到 1/2 大小,通道数不变 |
Conv3d(非分解卷积) |
kernel_size=1, stride=1 |
(B, C_out, H/2, W/2, D/2) |
调整通道数到 C_out,尺寸不变 |
2. 经过 ConvBlock
以下是单个 ConvBlock 的计算过程,输入数据维度为 (B, C_out, H/2, W/2, D/2) 。
| 步骤 | 参数 | 维度 | 备注 |
|---|---|---|---|
| 初始 | / | (B, C_out, H/2, W/2, D/2) |
输入数据(上一步输出) |
| DecompConv3D | stride=1 |
(B, C_out, H/2, W/2, D/2) |
保持尺寸不变 |
| 变换形状 | / | (B, H/2, W/2, D/2, C_out) |
将通道数移到最后 |
| MLP | hidden_dim=4*C_out |
(B, H/2, W/2, D/2, C_out) |
融合通道特征 |
| 缩放 | / | (B, H/2, W/2, D/2, C_out) |
通道特征乘上一个长度为 C_out 的可学习参数 |
| 变换形状 | / | (B, C_out, H/2, W/2, D/2) |
将通道数移回前面 |
| 残差连接 | / | (B, C_out, H/2, W/2, D/2) |
与经过 MLP 前的输入相加 |
然后,将上述 ConvBlock 再重复多次,得到最终输出。
DCFormer 总体架构
以代码中的 decomp_small 为例,整体架构如下:
|
|
其中包含 5 个阶段,其中第一个阶段是单个 DecomposedStem 模块,后面四个阶段是 ConvBlock 模块堆叠而成。
num_blocks=[1, 2, 3, 6, 2]:表示每个阶段堆叠的卷积块数量。channels=[64, 96, 192, 384, 768]: 表示每个阶段的输出通道数。
流程图如下(从上到下,从左到右):
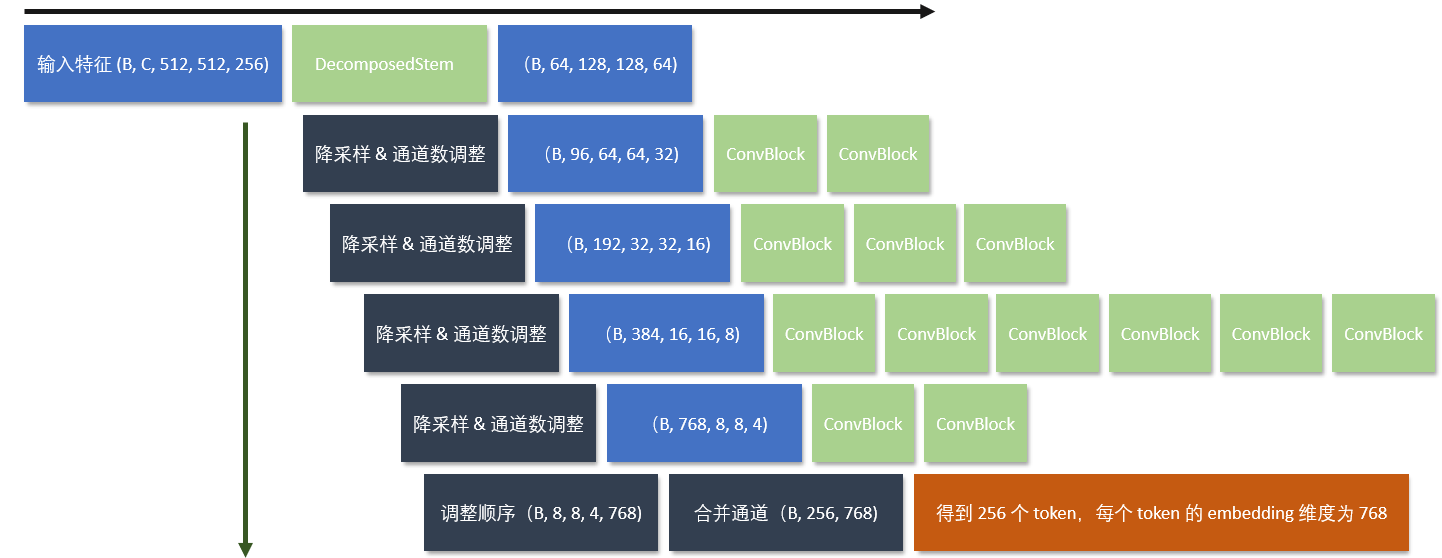
最后得到了 (B, 256, 768) 的图像特征向量,表示 256 个 token,每个 token 的维度为 768。
这个可以理解为,每个 token 对应图像中的一个局部区域,包含该区域的视觉信息。
Text-Encoder 文本编码器: BERT
BERT 是一种基于 Transformer 的预训练语言模型,能够有效地捕捉文本中的语义信息。
BERT 的输出包括两部分:
(B, L, D):每个 token 的特征向量,L为序列长度,D为隐藏层维度 (embedding 维度)。(B, D):[CLS] token 的特征向量,通常用于句子级别的表示,可以看作是整个文本的摘要。
Loss Function 损失函数: SigLIP
-
Vision-Encoder 输出的是图像特征向量
(B, L, D1),通过平均池化得到图像的全局特征向量(B, D1)。 -
Text-Encoder 输出的是文本的 [CLS] 特征向量
(B, D2)。 -
两者都要再进入一个线性变换层,映射到相同的维度空间
(B, D)。 -
然后两者进行归一化处理,得到单位向量,只保留方向信息。
-
目标: 让匹配的图像-文本对在向量空间中尽可能重合,而不匹配的对尽可能远离。这一点反映到点积运算上,就是让匹配对的特征向量点积尽可能大,而不匹配对的点积尽可能小。
设图像特征为 ,文本特征为 。
相乘得到相似度矩阵 :
这样, 表示第 个图像与第 个文本的相似度。
假设当且仅当 时,图像和文本是匹配的。我们可以构造标签矩阵 :
即正样本是 1,负样本是 -1。
计算损失函数:
相比于 normalized cross-entropy (NCE) 损失,SigLIP 损失对小 batch size 不敏感。
训练
解冻 Vision-Encoder 和 Text-Encoder 的所有参数,使用上述的对比损失函数进行训练。
数据集:M3D-Cap,包括 3D CT 扫描和对应的报告。所有 3D 体积缩放为 。
参数:
- batch , 学习率 ,权重衰减 ,训练 epochs .
- AdamW, warmup ratio = 0.03
- cosine learning rates cheduler
训练阶段二:VLM-Pretraining
这一阶段主要训练图像模态到文字模态的投影层。
Multi-Scale MLP-Mixer 多层次MLP混合器
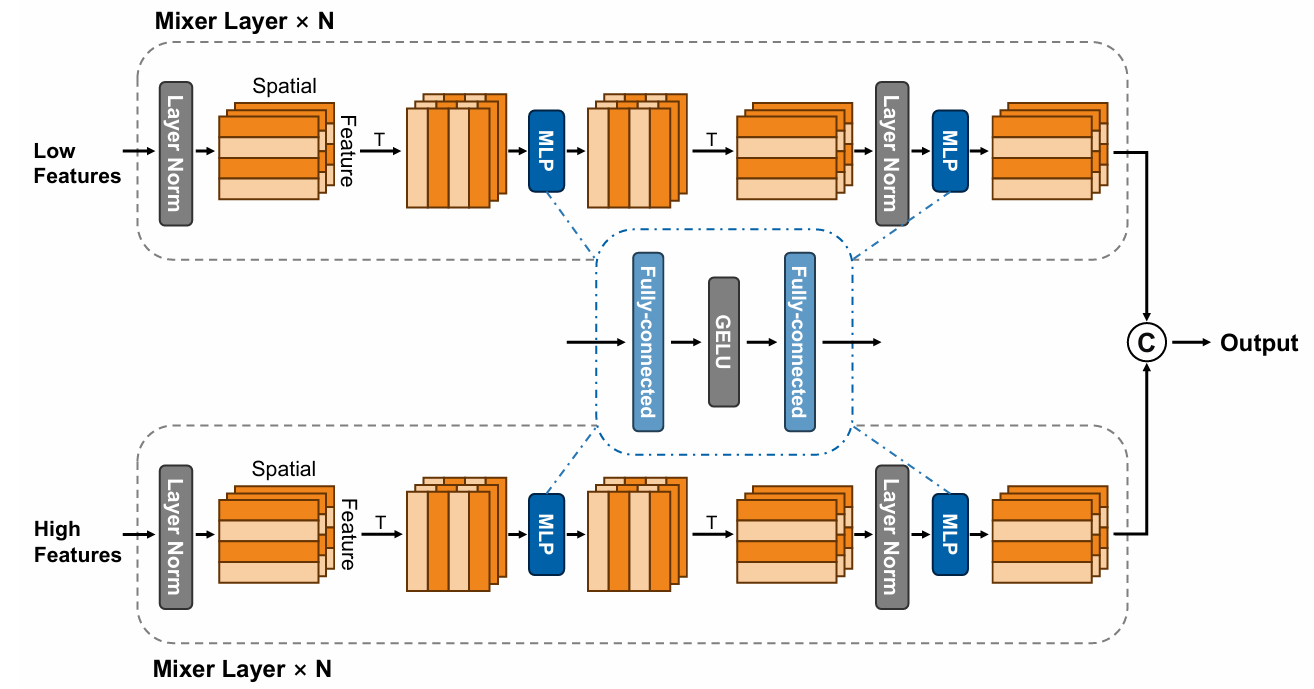
Mixer Layer 特征混合块 (空间 + 通道)
假设 DCFormer 最后输出了特征 (B, 32, 768) ,这可以理解为有 32 个 token,每个 token 代表了原图一个局部区域的特征,每个 token 的 embedding 维度即通道数量是 768 。
首先,进行空间特征混合,转置特征得到 (B, 768, 32) ,然后通过全连接层映射到 (B, 768, 64) ,经过激活函数 GELU,再通过全连接层,但不改变通道数,这样就完成了空间特征混合。这一部分 “全连接层-GELU-全连接层” 的结构是一个 MLP,即为上图中间部分。
然后,转置回 (B, 64, 768) ,进行通道特征混合,类似地,通过 MLP 映射到 (B, 64, 1792) 。
这样,就完成了一次 (B, 32, 768) -> (B, 64, 1792) 的转换,这个转换所在的结构被称为 Mixer Layer。论文中用了两个 Mixer Layer 叠起来,实现了 (B, 32, 768) -> (B, 64, 1792) -> (B, 128, 3584) 的转换,充分混合了空间和通道特征,这应该是一个上采样 Decoder 的结构。其中,128 表示空间特征,他们已经充分混合,很难说每一维代表了哪部分图像,但是可以作为图像总体的表示。3584 表示通道特征,为什么是这个数字呢?因为 Qwen2.5-7B 的 Embedding 维度就是 3584 ,这样就可以和 LLM 的输入对齐了。
所以,最终得到 (B, 128, 3584) 可以看作是用 128 个 token 描述了 DCFormer 的深层特征 (B, 32, 768) 。
高低层特征混合
DCFormer 的倒数第二层特征为 (B, 256, 384) ,我们称为低层特征 (low features) ,与之相对的,上面提到的最后一层特征 (B, 32, 768) ,我们称为高层特征 (high features)。
对 low features 和 high features 分别输入 Mixer Layer,可以得到两个 (B, 128, 3584) 的特征,将他们拼接在一起得到 (B, 256, 3584) ,这就是我们最终得到的描述图像的特征。
这个高底层特征混合的思路被作者认为是他们论文的核心创新点。
Qwen2.5-7B 适配
在 llm 的词表中插入一个特殊 token <im_patch> 表示图片 token 的占位符。
这样一段数据就变成:
|
|
理论上来说应该有 256 个 <im_patch> ,与上文中 256 个图片 token 一一对应。
训练的时候,在 embedding 之后把占位符 <im_patch> 换成图片 token 即可。
我们做实验的时候应该需要换成新版的 Qwen3,否则落后了。
训练
冻结 Vision Encoder 的所有参数,解冻投影层所有参数,只解冻 LLM 的 Embedding 参数,其余全部冻结。
数据集:M3D-Cap 和 M3D-VQA (yes/no 问答除外),图片为 3D 扫描,问题是自然语言询问,回答是自由格式的文本。
参数:batchsize , 学习率 , 无学习率衰减, epochs .
直接使用 transformers 的 LLM 训练器即可,原理大概为:
- 原始数据:
"图片左上方有肿瘤。" - 喂给模型
"图",让其预测"片"的概率,计算损失。 - 喂给模型
"图片",让其预测"左"的概率,计算损失。 - 喂给模型
"图片左",让其预测"上"的概率,计算损失。 - 以此类推……
训练阶段三:VLM Fine-Tuning
LoRA 微调
原理如下:
对于一个线性的环节,前向传播可以这样表示(假设已结合偏置项):
其中 是输入特征, 是权重矩阵, 是输出特征。
假设 ,参数量为 ,调节所有参数奢侈的。因此,我们引入两个较小的矩阵 和 ,其中 。新的权重矩阵表示为:
这样,我们只需要学习 和 的参数,参数量变为 ,大大减少了需要调节的参数数量。这就是 LoRA 的核心思想。
我们可以对 LLM 中的所有线性环节都应用 LoRA,从而达到微调整个模型的目的。
实际应用中公式为:
其中 是一个缩放系数。
训练
冻结 Vision Encoder ,解冻投影层和 LLM 的 LoRA 参数,解冻 LLM 的 embedding 参数和输出层参数。
数据集:M3D-Cap 和 M3D-VQA 。
参数:
- LoRA: Rank = 16, = 32, Dropout = 0.1
- batchsize , 学习率 , 无权重衰减, 训练 epochs .