Qwen3-0.6B 学习笔记

Contents
0 Qwen3 Technical Report
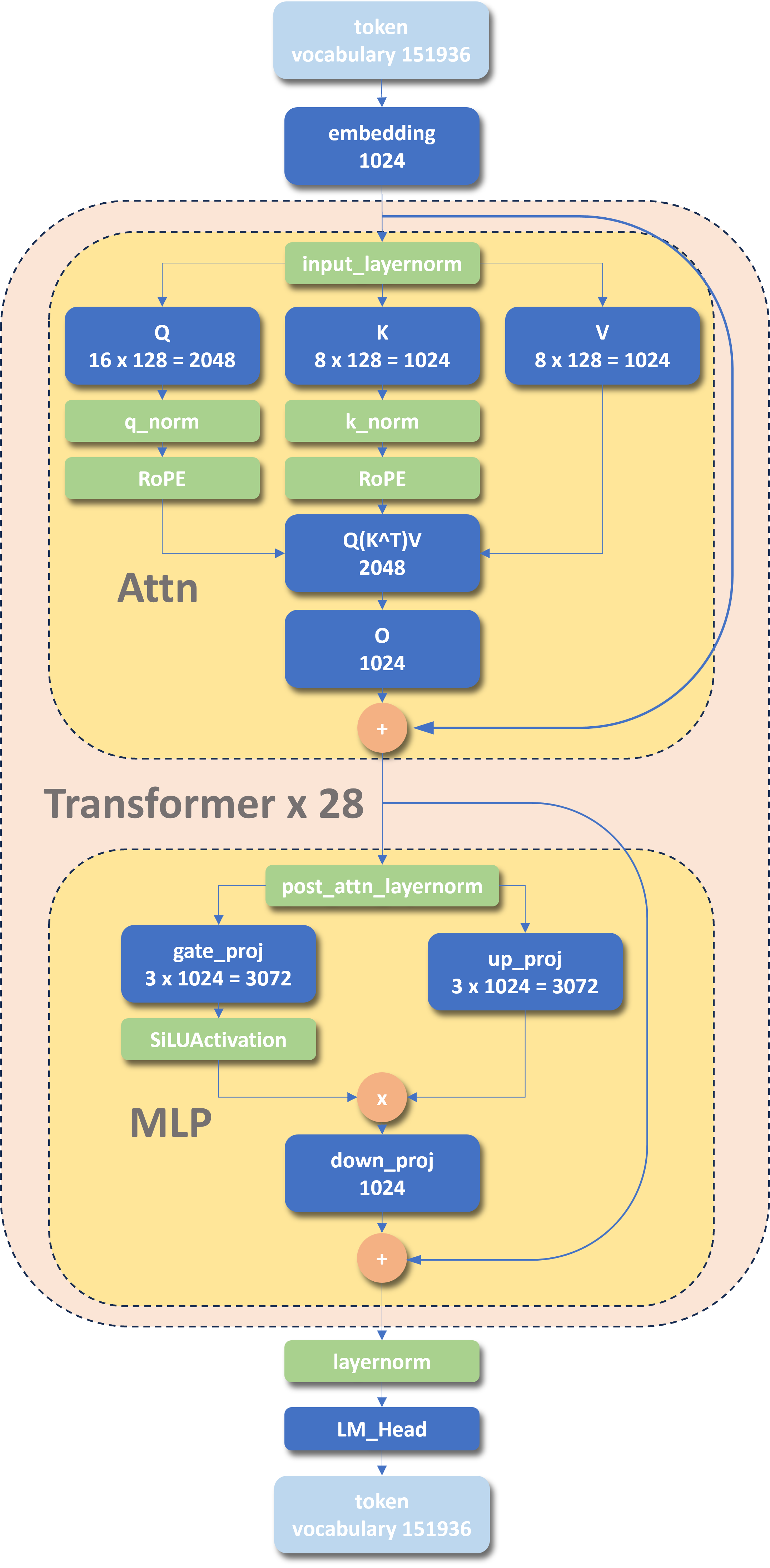
Qwen3 稠密模型与 Qwen2.5 相似,共同特点是:
- 分组查询头 (Grouped Query Attention, GQA) ,即多个 Q-head 共享同一组 KV 。
- SwiGLU,替代了传统 transformer 中简单的 MLP 。
- 旋转位置编码 (Rotary Positional Embeddings, ROPE) ,用于对 Q-head 和 K-head 注入位置信息。
- RMSNorm,均方根归一化。
- pre-norm,主要是针对残差连接的。数据输入后,先归一化,再进入模块计算,最后加上原始输入。与之相对的是 post-norm,表示数据输入后,先进入模块计算,再加上原始输入,最后统一归一化。pre-norm 可以避免训练时梯度消失。
不同点:
- 溢出了 QKV-bias 。
- 引入了 QK-Norm 。
主要参数:
| Models | Layers | Heads(Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
其中 Tie Embedding 表示 Embedding 和 解 Embedding 共享权重。
1 打印模型结构
可以使用 modelscope 上面的模型,无须代理或镜像,速度较快。需要按照 modelscope 和 transformers 库。
运行以下代码可得到模型的基本配置:
|
|
输出为:
|
|
看懂该 config,需要对 LLM 的主流结构有一定了解,而事实上他们是大同小异的,可参考:Transformer Explainer: LLM Transformer Model Visually Explained
关注点:
"head_dim": 128表示注意力头的维度。"hidden_size": 1024表示隐藏状态大小,即 embedding 的维度。"num_attention_heads": 16, "num_key_value_heads": 8一共有 16 组注意力头,但是 KV 头只有 8 组,说明使用了分组注意力,16 个 Q-head 共享 8 组 KV 。intermediate_size": 3072表示 MLP 中间隐藏层的维度,其中正好是hidden_size的 3 倍。事实上,该值之前一般取 4 倍hidden_size,但是由于 SwiGLU 的参数是朴素的 MLP 的 1.5 倍,将intermediate_size调小有助于平衡参数量。"num_hidden_layers": 28表示隐藏层的数量,这里指的是中间 Transformer 模块的堆叠的数量。"tie_word_embeddings": true表示 embedding 和解 embedding 共享权重。"vocab_size": 151936词表大小为 151936 .
进一步的,可以打印第一个 block 来查看结构:
|
|
输出为:
|
|
这里很清晰了,到 transfomers 库里面找相应 class 的源码可以进一步了解,不再赘述。
2 模型结构整理
模型结构整理如下: